大きなファイルを開く速度
ページャーはファイルを開くのは一瞬で表示するため、単純な速度比較は難しいですが、ovはページャーの中でも大きなファイルを快適に表示できます。
まず、一般的なページャーはエディターと違い大きなファイルを扱えるように設計されています。 ページャーが大きなファイルを素早く開いて表示できるのは、以下のような理由があります。
- ファイル全体をメモリにロードする前に表示
- seekを使って開く位置を指定
これにより、非常に大きなファイルでも先頭からの表示だけでなく、最後尾の表示も一瞬で表示できます。 ただし、seekにより指定はbyte単位の指定のため、行単位で指定したり行番号を表示するためには、行数をカウントする必要があります。
lessでは、大きなファイルでも先頭からだけでなく最後尾の表示も一瞬で表示できますか、行の計算が必要になる移動をしたときに動作を止めてカウントするため、一時停止が発生します。
ovのメモリ管理
ovでは、seekできる通常ファイルは全体を読み込まず、必要になった部分だけを読み込んで表示し、不要なメモリは開放するようになっています。
ovのファイルの読み込みの方法は、まずファイルを読み込む用のスレッド(goroutine)を立ち上げ、非同期にファイルの内容を読み込みます。
読み込みは、一定の行(10,000行)毎にChunkに分けて管理しています。
最初に先頭の10,000行以下のファイルの内容はメモリにロードされます。
10,000行以上ある場合は、まず先頭の10,000行までメモリにロードし、それ以降は行数を数えて10,000行毎のbyte位置をChunkとして管理し、メモリにロードしないで位置だけ憶えておきます。
10,000行以上先に移動するときには、以下の順をたどって指定された行を表示します。
- 行数から該当のChunkを特定
- その位置に
seek - 該当のChunkをメモリにロード
lessと比較してみます。
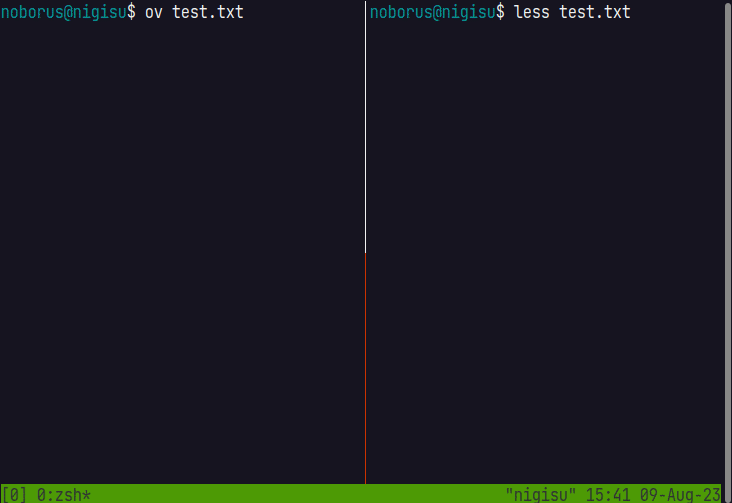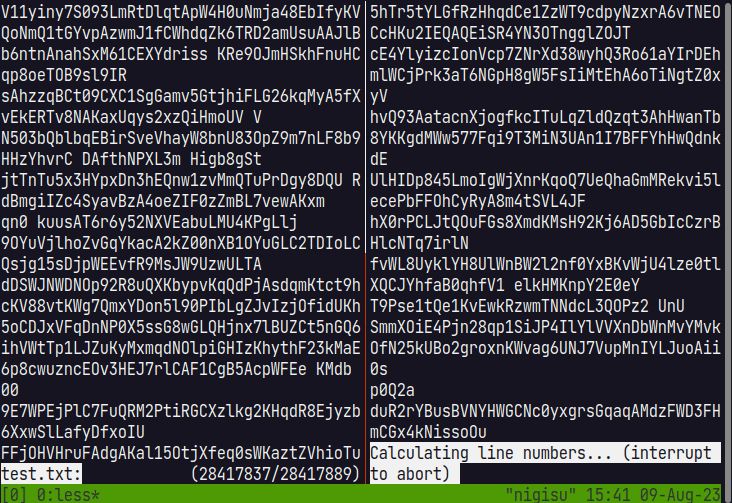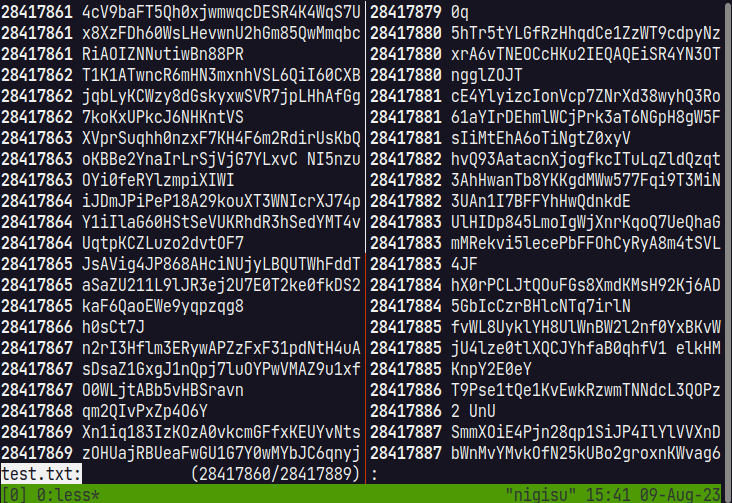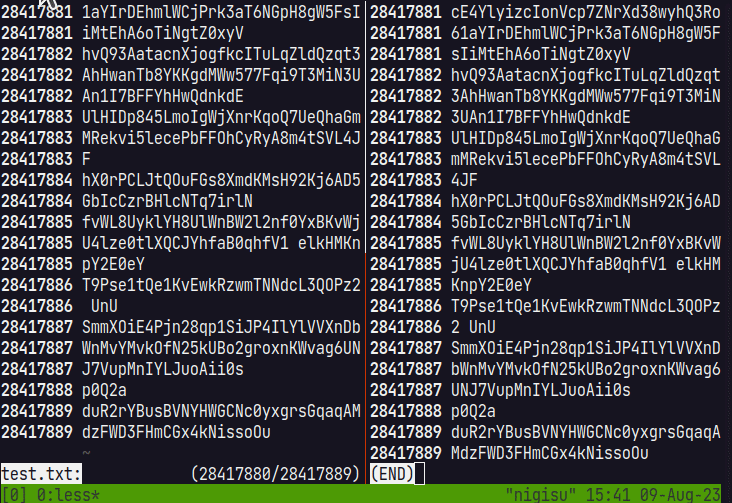
ただ、これだと数え終わる前に最後尾まで移動できないため、最後尾への移動は特別に一時Chunkを作成して、seekして最後尾の表示をできるようにしています。 ファイルを読み込んで数え終わるスレッドが終了すると、一時Chunkから実際のChunkに切り替えて表示します。
ファイルの読み込み
ファイルの読み込み方法も実際に読み込む場合と行数を数える場合で変えています。
先頭のChunkでは行末まで読み込み、スライスに保存しますが、行数を数えるChunkの場合は、一定のバッファサイズ分をreadして、その間の改行の数を数えて行数とbyte位置を必要なときに記録するだけです。
そのため、wc -lの動作に近い動きになっています。
ovでは前述の通りファイルの読み込みは別スレッドで行われているため、ユーザーの操作を妨げずにこれらの処理が裏側でおこなわれています。
以上の実装により、ovは大きなファイルを快適に開くことができます。