speed of opening large files
The pager is designed to display files instantly, so it is difficult to make a simple speed comparison, but ov can comfortably display large files even among pagers.
First of all, unlike editors, pagers are designed to handle large files. The reason why pagers can quickly open and display large files is as follows.
- Display before loading the entire file into memory
- Specify the position to open using seek
This allows large files to be displayed instantly, not only from the beginning but also from the end. However, since the specification by seek is in bytes, counting lines is necessary to specify by line or display line numbers.
In less, large files can be displayed instantly from the beginning to the end, but when moving to a position that requires line calculation, the operation stops to count, causing a pause.
Memory management of ov
In ov, for normal files that can be seeked, only the necessary parts are read and displayed without loading the entire file, and unnecessary memory is released.
The method of reading files in ov is to first launch a thread (goroutine) to read the file and read the contents of the file asynchronously.
The reading is managed by dividing it into Chunks every certain number of lines (10,000 lines).
The contents of the file up to the first 10,000 lines are loaded into memory.
If there are more than 10,000 lines, the first 10,000 lines are loaded into memory, and the remaining lines are counted, and the byte position every 10,000 lines is managed as a Chunk, remembering only the position without loading it into memory.
When moving more than 10,000 lines ahead, the specified line is displayed by following the following steps.
- Identify the corresponding Chunk from the line number
seekto that position- Load the corresponding Chunk into memory
Let’s compare it with less.
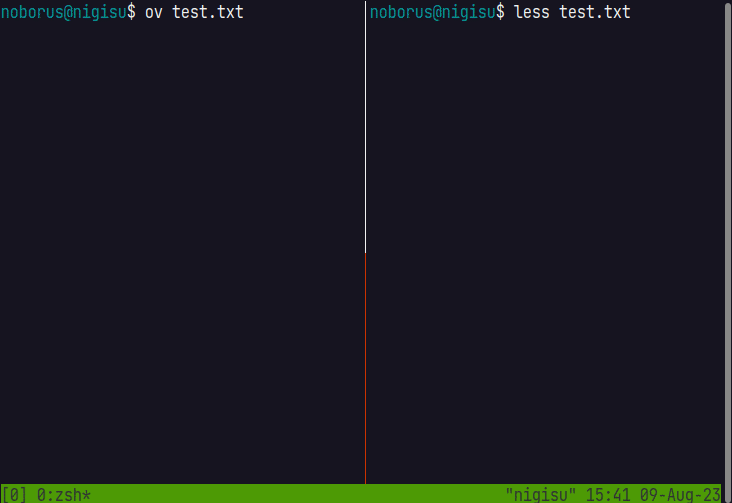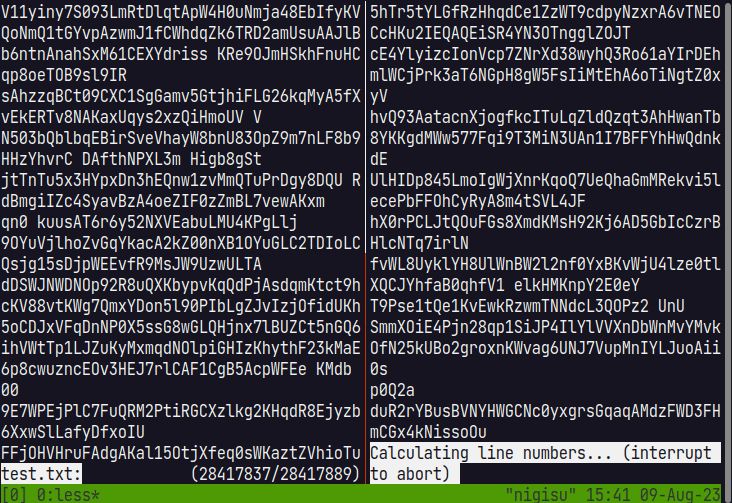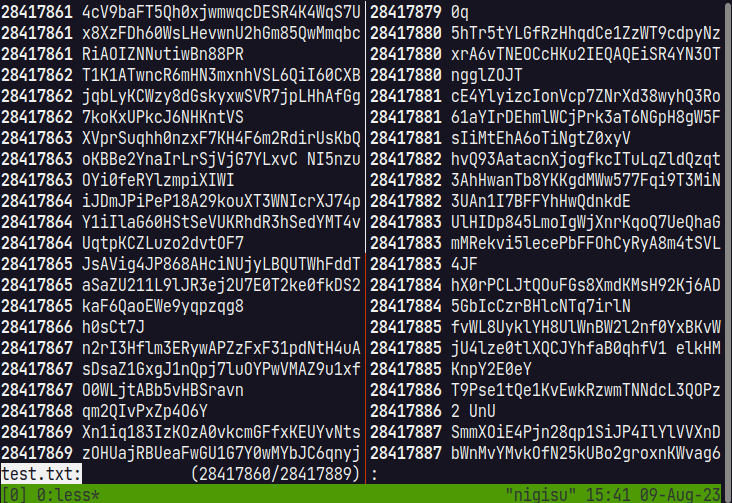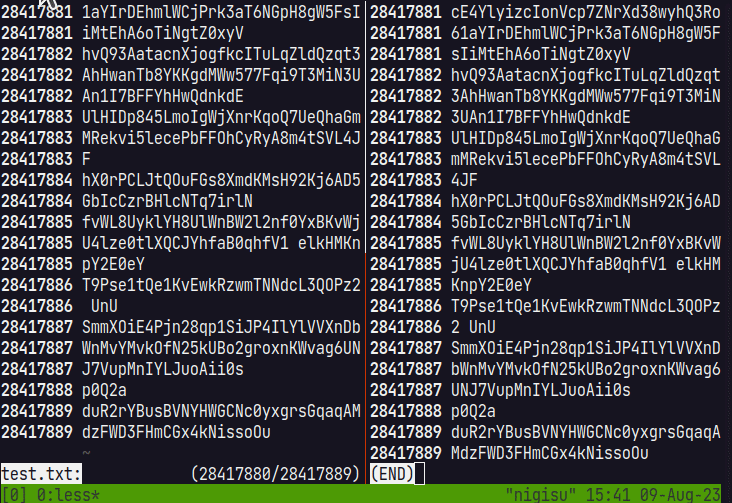
However, since it is not possible to move to the end before counting is completed, a temporary Chunk is created for moving to the end, and the display of the end is enabled by seeking. When the thread that reads the file and counts is finished, the display is switched from the temporary Chunk to the actual Chunk.
Reading files
The method of reading files is different depending on whether the file is actually read or the number of lines is counted.
In the case of the first Chunk, the file is read to the end of the line and saved in a slice, but in the case of the Chunk that counts the number of lines, a certain buffer size is read, the number of newlines in between is counted, and the line number and byte position are recorded only when necessary.
Therefore, it behaves similarly to wc -l.
As mentioned above, file reading in ov is done in a separate thread, so these processes are performed in the background without interfering with user operations.
With the above implementation, ov can comfortably open large files.